AWS DeepRacer is a fun way to begin practicing and exploring machine learning, particularly reinforcement learning.
While there are a lot of approaches to creating a reward function based on your goal, I discovered that integrating the “waypoints” parameter within the reward function allowed me to develop a relatively stable model.
In my experiment, although it might not result in the fastest model, this reward function intriguingly maintained an almost constant zero off-track rate for my car.
Here’s how I did it.
目次
Download Waypoints Files for DeepRacer Tracks
In case you’re unaware, there’s a dedicated community of DeepRacer enthusiasts called the AWS DeepRacer Community. They often provide some insightful tutorials and information related to DeepRacer.
To access the desired waypoints files, let’s visit the AWS DeepRacer Community’s GitHub page and find the specific track we’re interested in.
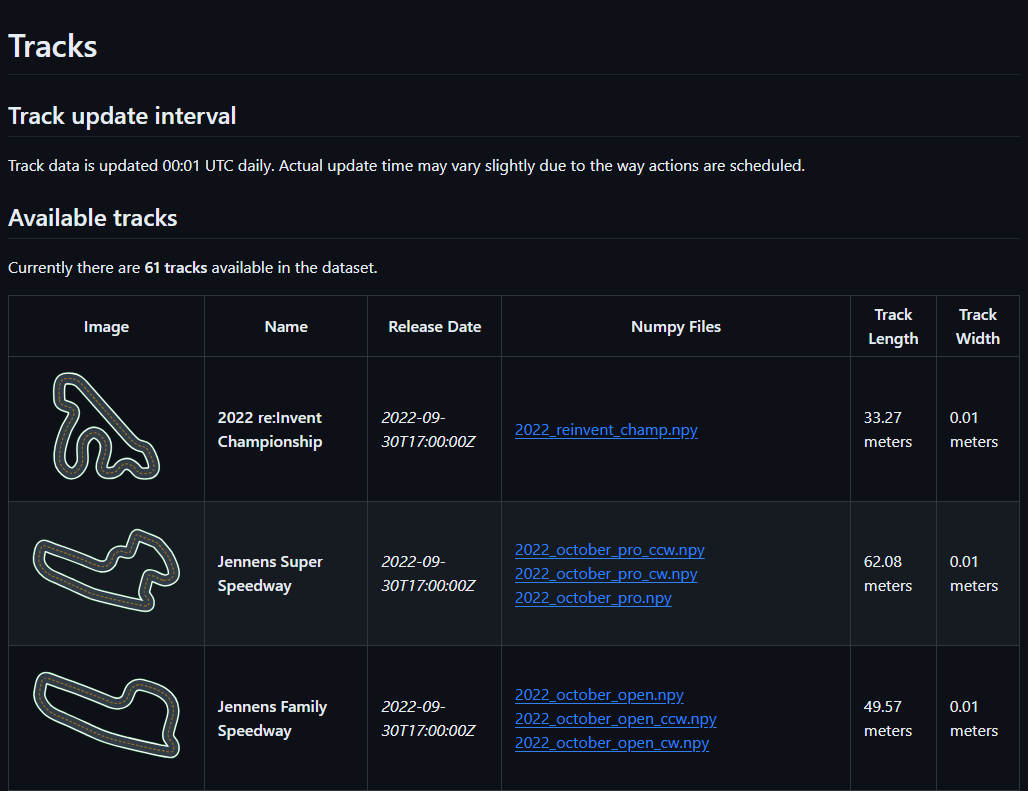
In this example, let’s choose Smile Speedway track.
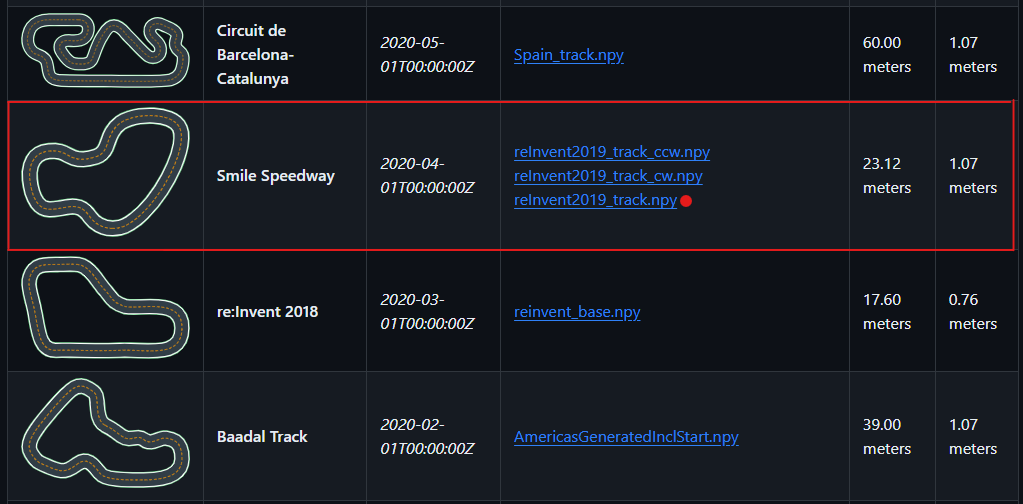
Let’s download the numpy file by clicking the View raw button.
View the Track Waypoints
For plotting the track, you can utilize either Jupyter Notebook or Google Colab. In this blog, I’ve opted for Google Colab.
Execute the following code to upload the file to your Google Colab notebook.
|
1 2 |
from google.colab import files uploaded = files.upload() |
This will generate a “Choose File” button allowing you to select a numpy file from your local computer. The track numpy file downloaded earlier is named ‘reInvent2019_track.npy’, so let’s select that.

We’ll visualize our track waypoints using blue dots on the plot.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
import numpy as np import matplotlib.pyplot as plt # Load the .npy file waypoints = np.load('reInvent2019_track.npy') # Visualize the waypoints plt.figure(figsize=(8, 8)) plt.scatter(waypoints[:, 0], waypoints[:, 1], c='blue', marker='o', label='Waypoints') plt.xlabel('X Coordinate') plt.ylabel('Y Coordinate') plt.title('AWS DeepRacer Track Waypoints') plt.legend() plt.grid(True) plt.axis('equal') # Set equal aspect ratio plt.show() |
It should look something like this.
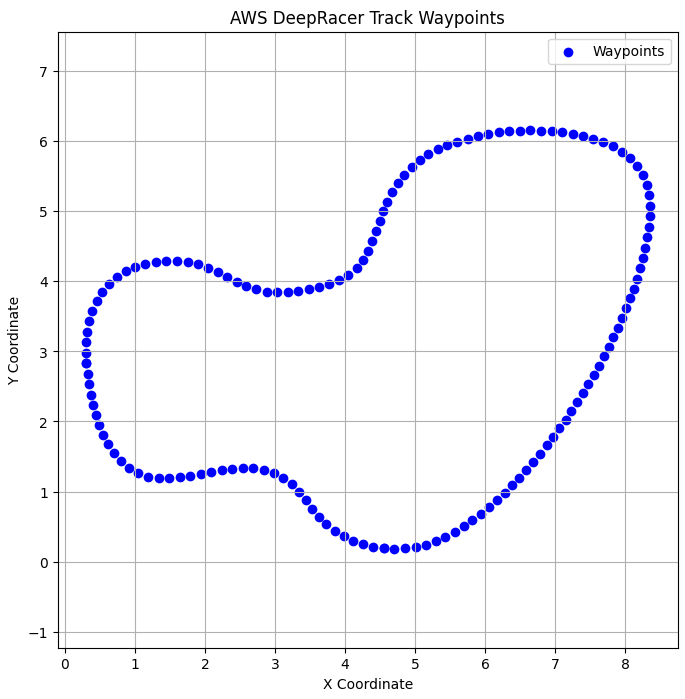
Now, rather than displaying the waypoints as blue dots, let’s visualize them using numerical labels to precisely identify the locations of the curves.
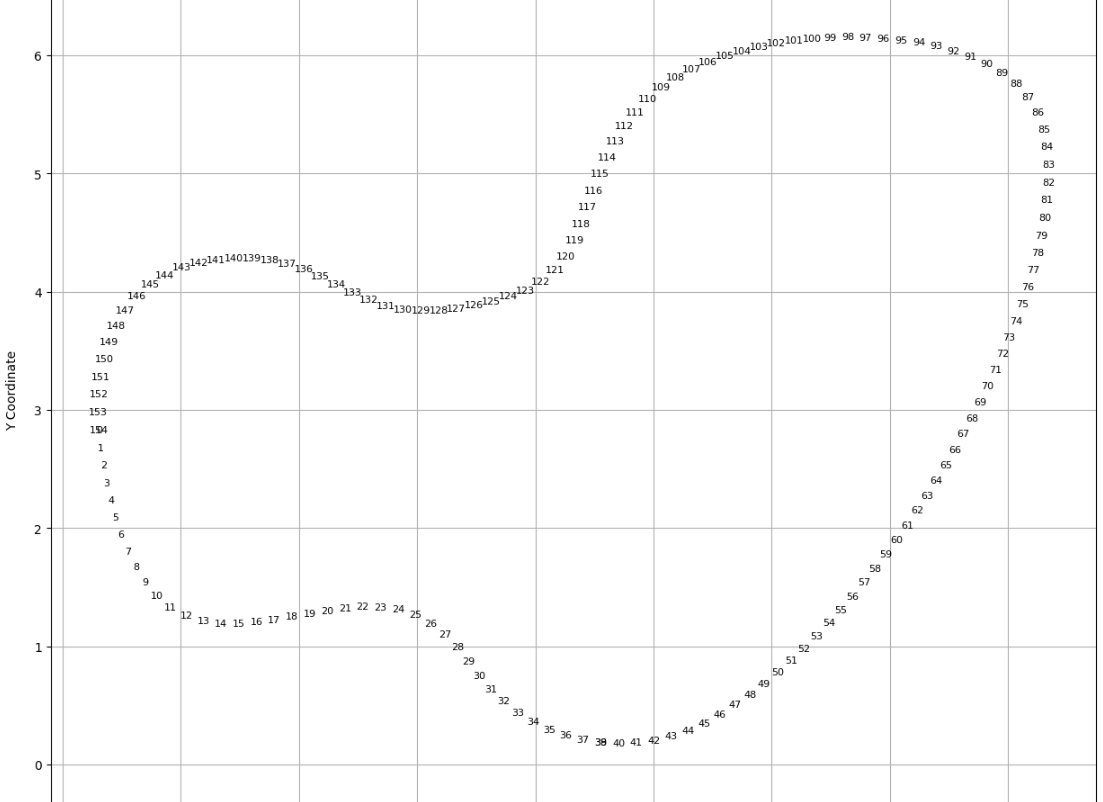
Now that we’ve successfully displayed the numbered waypoints, let’s proceed to the next step.
Reward Function
Within this function, I minimized the break_speed as a penalty. I specifically targeted two of the most challenging curves, namely those between 77-99 and 117-150.
To ensure the car slows down while turning, I established a condition: if the car’s speed exceeds 2.5 during these curves, it incurs a penalty; otherwise, it receives a reward based on its speed.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
break_speed = 0.01 def reward_function(params): ''' rewarding based on its speed ''' wp = params['closest_waypoints'][1] speed = params['speed'] if wp in (list(range(77, 90))): if speed >= 2.5: reward = break_speed if wp in (list(range(117, 150))): if speed >= 2.5: reward = break_speed reward = speed return float(reward) |
This approach encourages the car to maintain maximum speed while delicately slowing down during turns, preventing it from going off-track.
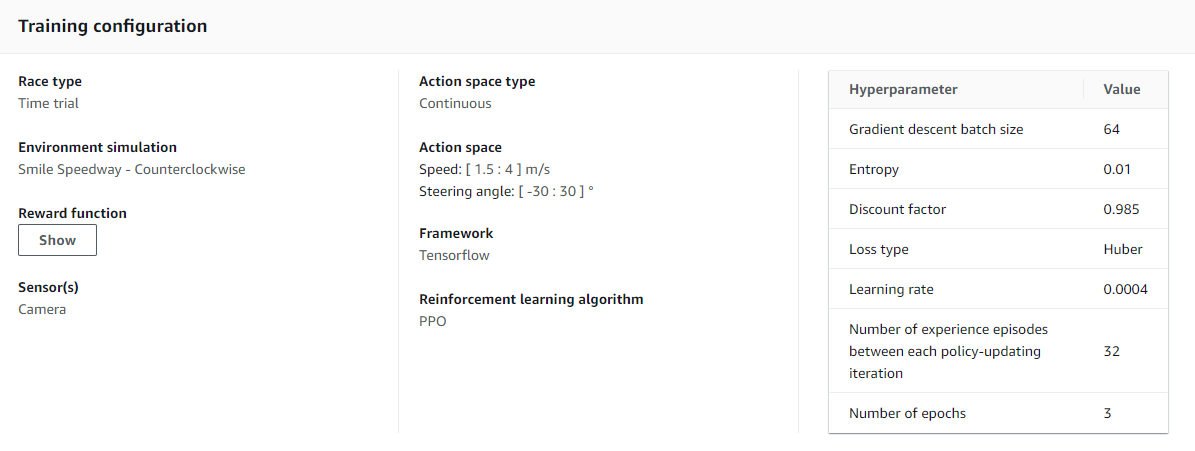
If you’re curious, here’s a glimpse of the training configuration.
Here’s how the graph appears after three hours of training. Perhaps stopping the training at the two-hour mark would have yielded better results.
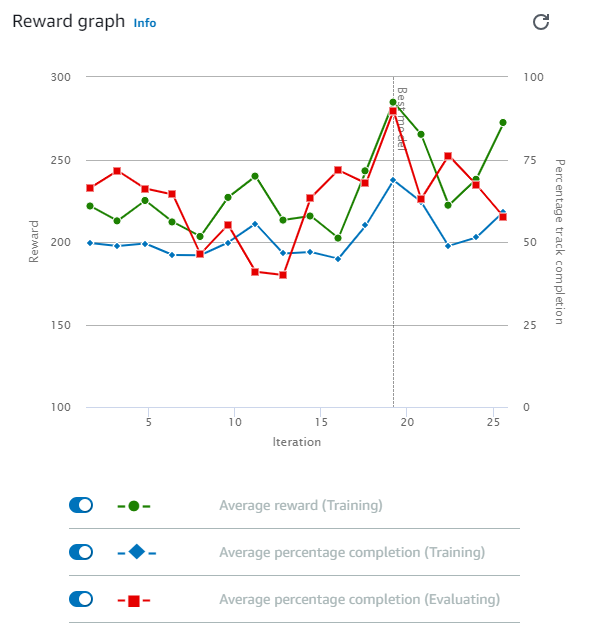
Now, let’s have a look at the evaluation result.

The car ran relatively smoothly and remained stable throughout. Additionally, in this evaluation, the car never veered off-track for 5 consecutive attempts.
Conclusion
While it may not achieve the highest speed, crafting a reward function utilizing waypoints, as demonstrated above, contributes to achieving a consistently smooth and stable drive across various tracks. Feel free to adapt and experiment with the code and training time to explore further possibilities!
For exploring additional DeepRacer reward function input parameters, click here.
- 【2024】AWS Jr.Championsを振り返る - 2025-07-01
- 中級figma教室 - 2024-12-24
- おすすめガジェット紹介!2024年12月編 - 2024-12-21
- 【Amazon RDS】意図せず突発的な再起動が起こった原因 - 2024-12-19
- Amazon ConnectでNGワードをリアルタイムに検知してSlackに通知する - 2024-12-16
【採用情報】一緒に働く仲間を募集しています