目次
ロボット型検索エンジンの仕組み
「GS1 Web Vocabulary」を理解いただくにあたり、まず最初に検索エンジンの仕組みを理解する必要がある。よく利用されている検索エンジンのほとんどが「ロボット型と呼ばれる仕組み」と「Webサイト制作者からの直接的な情報収集」を採用している。
- ロボット型と呼ばれる仕組み -
企業や個人が作成したwebサイトを検索ロボットと呼ばれるプログラムが自動で巡回し、情報を収集しデータベースに蓄積する。検索順位は、webサイト内に記載されている単語やアクセス数、被リンク数、更新頻度といった項目を基にアルゴリズムがランク付けを行う。そして、ユーザが検索を行った際に、検索ワードに適したwebサイトをランクが上位のものから検索結果として表示する。
- Webサイト制作者からの直接的な情報収集 -
検索エンジンでは、単に検索ロボットによる情報収集のみではなく、webサイト制作者からの直接的な情報収集にも取り組みを始めた。具体的には、sitemapの送信やGoogleマイビジネスといったサービスが挙げられる。
-検索エンジン対策の進化形「セマンティックweb」 -
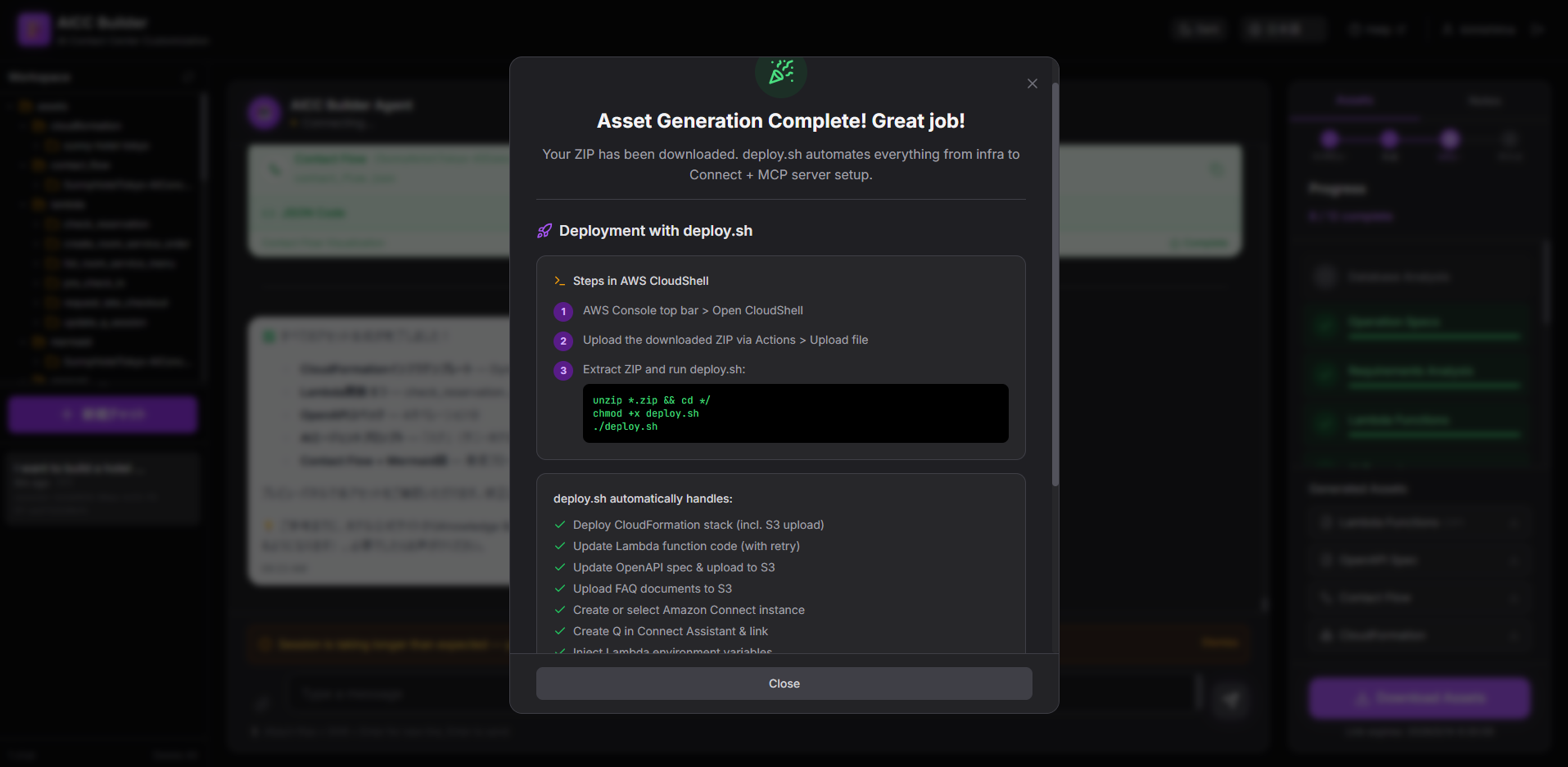
webサイトのソースコードに、コンピュータが読むための「構造化データ」を記載することで、検索ロボットに対し、より正確な情報を伝達できる技術である。
セマンティックwebで記載した情報は、Internet ExplorerやFirefox、Chromeといった消費者が見るwebブラウザ画面上では表示されないため、消費者に見せる情報や表現には一切影響を与えずSEO対策をすることができる。
Schema.orgとGS1 Web Vocabulary
セマンティックwebで利用される構造化データの書き方にはいくつか種類があるが、その中で広く採用されているのが「Schema.org」である。
これはGoogleやYahoo!、Microsoftなどが共同で進めているプロジェクトで、セマンティックwebにおける構造化データの書き方を定義し公開している。このことは、検索エンジンが構造化データを重視していることを示している。そして、GoogleやSchema.orgなどと協力し、構造化データで商品情報を書くための標準仕様、”GS1 Web Vocabulary”を定義した。これは2016年の2月にSchema.orgから”The first external extension”として公認され、web上のディファクト・スタンダードとして認知されている。
※GS1とは、複数の地域にまたがるサプライチェーンの効率と透明性を高めるため、国際規格を設計・策定する国際組織。
※「GS1 Web Vocabulary」とは、GoogleやSchema.orgとGS1が協力し作成した、構造化データで商品情報を書くための標準仕様。
構造化データ(Web Vocaburary)の有無による検索順位への影響結果
実際に弊社で検証を行ったデータとして、ほぼ完全一致するページに対して、構造化データが有るページと無いページで比較してみると、Google検索の場合68.3%の割合で、Bingの場合61.3%の割合で構造化データ有の商品ページの方が高い評価を受けていた。
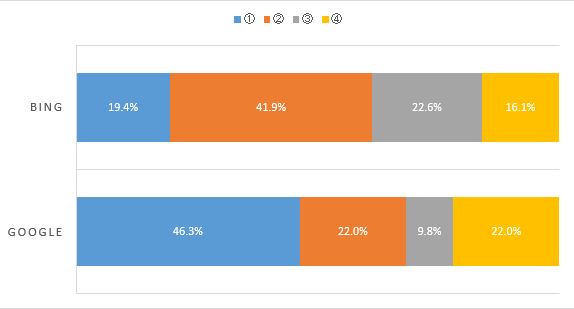
上記表の①~④の説明は、以下のとおりです。
前提条件として、類似した商品ページをそれぞれ作成し、構造化データを設置したページと設置していないページを用意し、どちらが上位に表示されるか検証した。
①構造化データを設置したページが検索にかかり、構造化データを設置していないページは検索されない
②構造化データを設置したページが構造化データを設置していないページよりも上位に表示された
③構造化データを設置していないページが検索にかかり、構造化データを設置したページは検索されない
④構造化データを設置していないページが構造化データを設置したページよりも上位に表示された
構造化データを設置したページが、設置していないページよりポジティブに働く可能性が高いことが言える。
次回は、実際に「GS1 Web Vocaburary」による構造化データの作成方法をまとめる。
- ゲームの中に「ビジネスの縮図」を見た話 - 2026-03-22
- XCALLYがメジャーバージョンアップするのでウェビナーに参加してみた - 2022-01-20
- 0120番号をクラウドPBXで利用するための基本的な作業手順 - 2021-06-03
- Kamailioとはなにか - 2021-04-21
- RFPの発注者とベンダー、両方の立場を並行で仕事してみて思うこと - 2020-12-09
【採用情報】一緒に働く仲間を募集しています