目次
本記事の目的
こんにちは、エンジニアのYokomachiです。
昨今LLM(大規模言語モデル)を活用したアプリケーション開発のアプローチとしてDifyやGumloop、Makeなどによるノーコード・ローコードによる開発もだいぶメインストリームになりつつある印象です。
弊社ギークフィードも先日Makeのオフィシャルパートナーとなり、社内活用や案件導入も進んできています。
が、今回はよりマニュアルにコードを書いてアプリケーション開発するために、LLMアプリケーション開発向けのライブラリ「LangGraph」を使ったマルチエージェントの開発に入門してみたいと思います。
LangGraphとは?
「LangGraph」は同じくLLMアプリ開発向けのライブラリ「LangChain」をベースに、ステートフルなマルチアクターアプリケーションを構築するために作られたライブラリです。
噛み砕くと、ユーザーの入力内容やワークフロー内の処理結果などを状態として保持し、そのデータに応じて動的に振る舞いを変えるアプリケーションを構築するためのライブラリ、ということになります。
LangGraphの特徴を挙げてみます。
- LangChainは一方向にタスクを処理する構造であるのに対し、LangGraphはサイクル(ループ)を含むフローをサポート
- LangChainはシンプルなワークフロー向け、LangGraphはより複雑で複数のエージェントが連携するワークフロー向け
- LangGraphはワークフローに人間が介入し、エージェントが計画した次のアクションを承認または中断することが可能
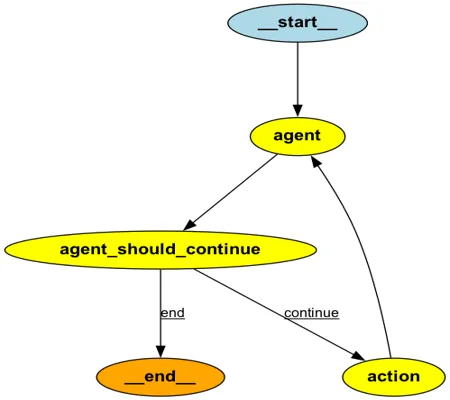
また、LangGraphはその名の通りエージェントのワークフローをグラフで定義します。
このグラフは、Nodes(点)とEdges(線)で構成され、各NodeやEdgeで使用される情報はStateで管理されます。
State: アプリケーションの現在のスナップショットを表す共有データ構造。 Pythonの型は何でもかまいませんが、通常はTypedDictかPydantic BaseModelです。
Nodes: エージェントのロジックをエンコードするPython関数。 現在のStateを入力として受け取り、何らかの計算や副作用を実行し、更新されたStateを返します。
Edges: 現在のStateに基づいて、次に実行するNodeを決定するPython関数。 条件分岐であったり、固定遷移であったりします。
グラフのイメージは以下のようになります。
導入
チュートリアルの内容について
今回はLangGraphの公式サイトで公開されているQuick Startの内容を、上から順にやっていきたいと思います。
このQuick Startは全部で7パートからなり、最初は単純なチャットボットを構築し、パートを経るごとにLangGraphの特徴的な機能を少しずつ追加していく形のチュートリアルとなっています。
最終的にはTool use、Checkpoint、Human-in-the-loop、Time Travelをサポートするチャットボットが出来上がります。
また、ユーザーの入力制御周りに関してはQuick Startの内容からカスタマイズしています。
各セクションでコードの内容の説明はしていきますが、全体のコードはGithubで公開していますのでこちらもご覧ください。
https://github.com/n-yokomachi/langgraph_tutorial_with_bedrock
構成図
構成図は以下の通りとなります。
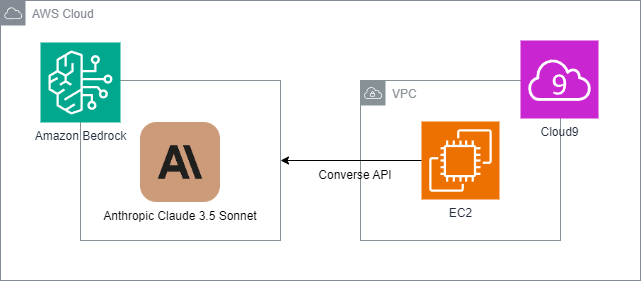
LLMアプリケーションとなるPythonスクリプトはCloud9上で開発を行います。
Quick StartのサンプルコードではAnthropicのAPIを利用していますが、今回はAmazon BedrockのAnthropic Claude 3.5 Sonnetを利用できるように若干コードをカスタマイズします。
なお、BedrockのAPIはモデル間でパラメータが統一されているConverse APIを使用します。
動作環境
OS:Amazon Linux release 2023.5.20240916
ライブラリ:requirements.txtを参照 (EC2上で全ライブラリについて書き出しているので不要なものも含まれます)
LLM:Amazon Bedrock Anthropic Claude 3.5 Sonnet (事前にAWSコンソール上でLLMを有効化しておく必要があります。)
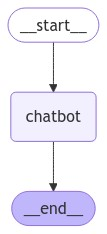
Part 1: Build a Basic Chatbot
このセクションではまず基本的なチャットボットの構築を行います。
ユーザーが入力したメッセージに直接LLMが回答して終了するだけのものです。
グラフは以下のとおりです。
コードの概要は以下の通りです。
- StateクラスでNodeなどで利用するオブジェクトと、その更新方法をreducer関数として定義
- chatbotという関数をgraph_builder.add_node()でNodeとして追加
- chatbotがinvokeするLLMはChatBedrockConverseでConverse APIを実行するように変更
- graph_builder.set_entry_point(), graph_builder.set_finish_point()でグラフの始点、終点をEdgeとして定義
- 最後のWhile文はこのグラフをチャットボットとして利用するためのインタフェース
- ソースコード
12345678910111213141516171819202122232425262728293031323334353637383940414243444546from typing import Annotatedfrom langchain_aws import ChatBedrockConversefrom typing_extensions import TypedDictfrom langgraph.graph import StateGraph, START, ENDfrom langgraph.graph.message import add_messages# StateクラスでNodeなどで利用するオブジェクトと、その更新方法をreducer関数として定義class State(TypedDict):messages: Annotated[list, add_messages]graph_builder = StateGraph(State)# chatbotがinvokeするLLMはChatBedrockConverseでConverse APIを実行するように変更llm = ChatBedrockConverse(model="anthropic.claude-3-5-sonnet-20240620-v1:0")def chatbot(state: State):return {"messages": [llm.invoke(state["messages"])]}# chatbot関数をgraph_builder.add_node()でNodeとして追加graph_builder.add_node("chatbot", chatbot)# graph_builder.set_entry_point(), graph_builder.set_finish_point()でグラフの始点、終点をEdgeとして定義graph_builder.set_entry_point("chatbot")graph_builder.set_finish_point("chatbot")graph = graph_builder.compile()def stream_graph_updates(user_input: str):for event in graph.stream({"messages": [("user", user_input)]}):for value in event.values():print("Assistant:", value["messages"][-1].content)# このWhile文はこのグラフをチャットボットとして利用するための入力制御while True:try:user_input = input("User: ")if user_input.lower() in ["quit", "exit", "q"]:print("Goodbye!")breakstream_graph_updates(user_input)except:user_input = "What do you know about LangGraph?"print("User: " + user_input)stream_graph_updates(user_input)break
実行結果は以下のようになります。
「langgraphとは何ですか?」という質問にLLMが自身の知識範囲で回答しています。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
User: langgraphとは何ですか? Assistant: LangGraphは、大規模言語モデル(LLM)を使用したアプリケーションを構築するためのPythonフレームワークです。以下にLangGraphの主要な特徴と概要を説明します: 1. 目的: LangGraphは、複雑なLLMベースのワークフローを作成し、管理するためのツールを提供します。 2. 主な特徴: - グラフベースのアーキテクチャ:タスクを個別のノードとして定義し、それらを接続してワークフローを作成します。 - 非同期処理:効率的な並行処理を可能にします。 ~(中略)~ LangGraphは、LLMを活用した複雑なシステムの開発を簡素化し、効率化することを目的としています。 User: q Goodbye! |
Part 2: Enhancing the Chatbot with Tools
このセクションではチャットボットにWeb検索ツールのNodeを追加します。
グラフは以下の通りです。
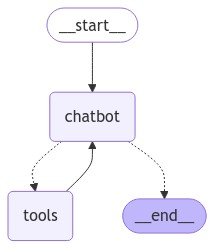
Part1からの変更点は以下の通りです。
- Web検索を行うAPIとしてTavily Search APIを使うように設定し、add_node()でNodeに追加
- bind_tools()でLLMが使えるToolの紐づけ(tool use)を定義
- 事前定義された関数tools_condition()を条件付きエッジとして定義(tools_condition()はLLM実行後のメッセージが「tool_calls」だった場合、toolsノードを呼び出すように定義されている)
- ソースコード
1234567891011121314151617181920212223242526272829303132333435363738394041424344# import省略# Tavily Search APIのAPIキーは.envファイルに記述し読み込むfrom dotenv import load_dotenvload_dotenv()class State(TypedDict):messages: Annotated[list, add_messages]graph_builder = StateGraph(State)# Web検索を行うAPIとしてTavily Search APIを使うように設定tool = TavilySearchResults(max_results=2)tools = [tool]llm = ChatBedrockConverse(model="anthropic.claude-3-5-sonnet-20240620-v1:0")# bind_tools()でLLMが使えるToolの紐づけ(tool use)を定義llm_with_tools = llm.bind_tools(tools)def chatbot(state: State):return {"messages": [llm_with_tools.invoke(state["messages"])]}graph_builder.add_node("chatbot", chatbot)# add_node()でtoolをNodeに追加tool_node = ToolNode(tools=[tool])graph_builder.add_node("tools", tool_node)# 事前定義された関数tools_condition()を条件付きエッジとして定義# (tools_condition()はLLM実行後のメッセージが「tool_calls」だった場合、toolsノードを呼び出すように定義されている)graph_builder.add_conditional_edges("chatbot",tools_condition,)graph_builder.add_edge("tools", "chatbot")graph_builder.set_entry_point("chatbot")graph = graph_builder.compile()def stream_graph_updates(user_input: str):# 省略while True:# 省略
実行結果は以下のようになります。
「langgraphとは何ですか?」と質問に対し、今度はWeb検索を実行してその結果を要約していることがわかります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
User: langgraphとは何ですか? Assistant: [{'type': 'text', 'text': 'langgraphについての最新の情報を検索するために、検索エンジンを使用してみましょう。'}, {'type': 'tool_use', 'name': 'tavily_search_results_json', 'input': {'query': 'langgraph とは何か'}, 'id': 'tooluse_SzdIl48OTny1Lk5on7r9fw'}] Assistant: [{"url": "<https://note.com/en2enzo/n/nd93fc9b60059>", "content": "LangGraph は、LLM を使用してステートフルなマルチアクター アプリケーションを構築するためのライブラリです。 ... 率直に、これだけだと何がうれしいかわかりにく いですが、このあと1つずつ理解しながら自分オリジナルのマルチエージェントを作って ..."}, {"url": "<https://zenn.dev/pharmax/articles/8796b892eed183>", "content": "Graph は、LangGraphの中核となるグラフ全体を管理するためのコンポーネント です。. 基本的な使い方としては、 StateGraph というクラスを使い、後述するStateとセットで初期化します。. (StateGraphの宣言例). from typing_extensions import TypedDict. from langgraph. graph import ..."}] Assistant: langgraphについての情報を検索した結果、以下のことがわかりました: 1. LangGraphは、LLM(大規模言語モデル)を使用してステートフルなマルチアクターアプリケーションを構築するためのライブラリです。 2. このライブラリは、複数のエージェント(アクター)を含むアプリケーションの開発を容易にします。 3. LangGraphの中核となるのは、グラフ全体を管理するためのコンポーネントであるGraphです。 4. 基本的な使い方として、StateGraphというクラスを使用し、Stateと呼ばれる要素とセットで初期化します。 5. このライブラリを使用することで、開発者は自分オリジナルのマルチエージェントシステムを作成することができます。 langgraphは比較的新しい技術で、LLMを活用した複雑なアプリケーションの開発をサポートするツールです。特に、複数のエージェントが相互作用する、より高度で動的なAIシステムの構築に役立ちます。 このライブラリは、AIの分野で注目されている「マルチエージェントシステム」の開発を簡素化し、より多くの開発者がこの分野に参入できるようにすることを目指しているようです。 User: q Goodbye! |
Part 3: Adding Memory to the Chatbot
このセクションではチャットボットにメモリを追加し、会話のコンテキストを保存できるようにします。
LangGraphではこのメモリをCheckpointと呼称し、会話履歴の保存だけではなく、グラフ全体の状態を保存し、グラフの中断や再開、エラーからの回復や、後述のhuman-in-the-loopやTime travel機能に活用できるようです。
まずは単純な会話保存としてのメモリを実装します。
グラフはPart 2から変更ありません。
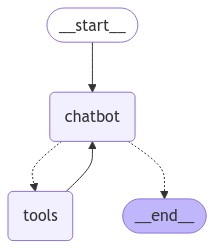
Part2からの変更点は以下の通りです。
- CheckpointerとしてMemorySaverをインポート
- MemorySaverをCheckpointerとして引数に渡してグラフをコンパイル
- チャットボットと会話する際にはスレッドIDを指定するように変更
- ソースコード
12345678910111213141516171819202122# import省略# MemorySaverをインポートfrom langgraph.checkpoint.memory import MemorySavermemory = MemorySaver()# 省略graph_builder.add_edge("tools", "chatbot")graph_builder.set_entry_point("chatbot")# チェックポインタとしてMemorySaverを使用してグラフをコンパイルgraph = graph_builder.compile(checkpointer=memory)# 会話で使用するスレッドIDを指定config = {"configurable": {"thread_id": "1"}}def stream_graph_updates(user_input: str):for event in graph.stream({"messages": [("user", user_input)]}, config):for value in event.values():print("Assistant:", value["messages"][-1].content)while True:# 省略
実行結果は以下のようになります。
最初にインプットした私の名前を記憶していることがわかります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
User: 私の名前はyokomachiです Assistant: こんにちは、yokomachi さん。お会いできて嬉しいです。 あなたの名前について教えていただきありがとうございます。日本語で会話されているようですが、何かお手伝いできることはありますか?例えば、最近のニュースや情報について知りたいことがあれば、検索エンジンを使ってお調べすることができます。 または、他に何か質問や話したいトピックがあれば、お聞かせください。私は様々な話題についてお話しすることができます。 User: 私の名前は何ですか? Assistant: あなたの名前は yokomachi です。 先ほどあなたが「私の名前はyokomachiです」とおっしゃいましたので、そのように理解しています。yokomachi さんと呼ばせていただいてよろしいでしょうか? User: q Goodbye! |
Part 4: Human-in-the-loop
このセクションではグラフのワークフローに人間が介入できるようにします。
interrupt_before機能を使用して、フローの中断を行い、人間が再開を指示できるようにします。
グラフは以下のようになります。
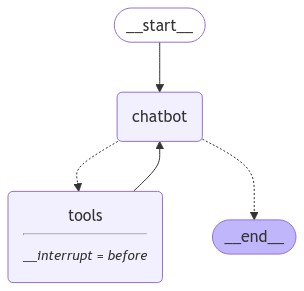
Part3からの変更点は以下の通りです。
- グラフのコンパイルの第二引数にinterrupt_beforeでtoolsを指定。これによりtoolsの使用前に中断が入るようになる
- 入力制御のロジックに、何も入力しなかったときはNoneをgraph.stream()の第一引数に渡すように処理追加。stream()にNoneが渡されたとき、中断部分からの再開指示となる。
- ソースコード
12345678910111213141516171819202122232425262728293031323334353637383940# 省略graph_builder.add_edge("tools", "chatbot")graph_builder.set_entry_point("chatbot")# interrupt_beforeを指定し、toolsの使用前に中断を入れるように設定graph = graph_builder.compile(checkpointer=memory,interrupt_before=["tools"])# 会話で使用するスレッドIDを指定config = {"configurable": {"thread_id": "1"}}# ユーザー入力がある場合def stream_graph_updates(user_input: str):for event in graph.stream({"messages": [("user", user_input)]}, config):for value in event.values():print("Assistant:", value["messages"][-1].content)# ユーザー入力がない場合はNoneを渡してstreaming# Noneが渡された場合、中断部分から再開するdef stream_graph_updates_by_none():for event in graph.stream(None, config):for value in event.values():print("Assistant:", value["messages"][-1].content)while True:try:user_input = input("User: ")if user_input.lower() in ["quit", "exit", "q"]:print("Goodbye!")breakelif user_input == "":stream_graph_updates_by_none()else:stream_graph_updates(user_input)except:user_input = "What do you know about LangGraph?"print("User: " + user_input)stream_graph_updates(user_input)break
実行結果は以下のようになります。
LLMの1回目の回答でいきなりTool useをせず、検索エンジンを使う提案が行われます。
その後、無入力でNoneを渡すとそれをGOサインとしてTool useを実行し、検索結果の要約を行っていることがわかります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
User: LangGraphについて教えてください Assistant: [{'type': 'text', 'text': 'LangGraphについて最新の情報を得るために、検索エンジンを使用して調べてみましょう。'}, {'type': 'tool_use', 'name': 'tavily_search_results_json', 'input': {'query': 'LangGraph 概要 最新情報'}, 'id': 'tooluse_1l5patw6Qy2oARo0WNLx7Q'}] User: Assistant: [{"url": "<https://note.com/npaka/n/n277702d13205>", "content": "本日 (2024年6月27日)、「LangGraph v0.1」と「LangGraph Cloud」をリリースしました。. 2. LangGraph v0.1. 「LangGraph」は、エージェントおよびマルチエージェントアプリケーションを構築するためのフレームワークです。. エージェントとは、LLMがアプリケーションの制御 ..."}, {"url": "<https://www.langchain.com/langgraph>", "content": "LangGraph sets the foundation for how we can build and scale AI workloads — from conversational agents, complex task automation, to custom LLM-backed experiences that 'just work'. The next chapter in building complex production-ready features with LLMs is agentic, and with LangGraph and LangSmith, LangChain delivers an out-of-the-box solution ..."}] Assistant: LangGraphについて、最新の情報を基に説明させていただきます。 LangGraphは、エージェントおよびマルチエージェントアプリケーションを構築するためのフレームワークです。これは、LangChainプロジェクトの一部として開発されており、2024年6月27日にバージョン0.1がリリースされました。 LangGraphの主な特徴と目的は以下の通りです: 1. エージェントの構築: LangGraphは、大規模言語モデル(LLM)を使用してアプリケーションを制御するエージェントの作成を可能にします。これにより、より高度で自律的なAIシステムの開発が可能になります。 2. マルチエージェントアプリケーション: 複数のエージェントが協調して動作するシステムの構築をサポートしています。これにより、より複雑なタスクや相互作用を必要とするアプリケーションの開発が容易になります。 3. AI ワークロードのスケーリング: LangGraphは、会話型エージェントや複雑なタスク自動化など、様々なAIワークロードの構築とスケーリングの基盤を提供します。 4. 生産環境への対応: LangGraphは、LangSmithと組み合わせることで、複雑な本番環境向け機能をLLMで構築するための「すぐに使える」ソリューションを提供します。 5. LangChainとの統合: LangChainプロジェクトの一部として開発されているため、LangChainの他のコンポーネントとシームレスに統合できます。 6. クラウドサービス: 「LangGraph Cloud」も同時にリリースされ、クラウド環境でのLangGraphの利用が可能になりました。 LangGraphは、AIアプリケーション開発の次のステージを見据えたフレームワークであり、特にエージェントベースのシステム構築に焦点を当てています。これにより、開発者はより高度で柔軟なAIシステムを効率的に構築できるようになります。 LangGraphは比較的新しいテクノロジーであるため、今後さらなる機能の追加や改善が期待されます。AI開発者やエンジニアにとって、注目すべきフレームワークの一つと言 |
Part 5: Manually Updating the State
このセクションではHuman-in-the-loopの一環として、グラフの状態を手動で変更する方法を実装します。
先ほどのようにLLMがTool useを提案した際に、ユーザー自身が手動で状態を変更し、LLMがすでに適切な回答をしたと判断させます。
具体的なシナリオとしては、まずユーザーが「LangGraphとは何か?」と質問をすると、LLMは「Webで検索してみましょう」と提案します。この状態に対して「『LangGraphとは~です』という回答をLLMがすでに回答した」という情報を手動で追加します。これによりLLMは、Tool useの必要がないと判断し会話を終了します。
グラフはPart5から変更ありません。
また、ソースコードに関してもグラフ自体のソースコードには変更ありません。
入力制御の部分で、中断が入った際に「update」を入力すると、グラフの状態を変更する関数を呼び出すようにコードを追加しています。
- ソースコード
123456789101112131415161718192021222324252627282930313233343536373839404142434445# 省略def update_graph_state():# 現在のLLMの回答を取得するsnapshot = graph.get_state(config)existing_message = snapshot.values["messages"][-1]# 追加する状態を定義するanswer = ("LangGraphはステートフルでマルチアクターなLLMアプリケーションを構築するためのライブラリです。")new_messages = [# LLM APIのツールの呼び出しに対応するToolMessageを手動で与えるToolMessage(content=answer, tool_call_id=existing_message.tool_calls[0]["id"]),# LLMの回答を手動で上書きするAIMessage(content=answer),]new_messages[-1].pretty_print()graph.update_state(config,{"messages": new_messages},)print("\\n\\nLast 2 messages;")print(graph.get_state(config).values["messages"][-2:])while True:try:user_input = input("User: ")if user_input.lower() in ["quit", "exit", "q"]:print("Goodbye!")breakelif user_input == "":stream_graph_updates_by_none()elif user_input == "update":update_graph_state()else:stream_graph_updates(user_input)except:user_input = "What do you know about LangGraph?"print("User: " + user_input)stream_graph_updates(user_input)break
実行結果は以下のようになります。
「LangGraphはステートフルでマルチアクターなLLMアプリケーションを構築するためのライブラリです。」というのはこちらが手動で追加したLLMの回答です。これによりTool useをせずにワークフローが完了しています。
|
1 2 3 4 5 6 7 8 9 10 |
User: LangGraphとは何ですか? Assistant: [{'type': 'text', 'text': 'LangGraphについての最新の情報を検索するために、tavily_search_results_json関数を使用してみましょう。'}, {'type': 'tool_use', 'name': 'tavily_search_results_json', 'input': {'query': 'LangGraph とは何か'}, 'id': 'tooluse_9DcvJhFZQuqpsupO5elo-w'}] User: update ================================== Ai Message ================================== LangGraphはステートフルでマルチアクターなLLMアプリケーションを構築するためのライブラリです。 Last 2 messages; [ToolMessage(content='LangGraphはステートフルでマルチアクターなLLMアプリケーションを構築するためのライブラリです。', id='0072f90a-d660-4db3-8533-6032557a03d2', tool_call_id='tooluse_9DcvJhFZQuqpsupO5elo-w'), AIMessage(content='LangGraphはステートフルでマルチアクターなLLMアプリケーションを構築するためのライブラリです。', additional_kwargs={}, response_metadata={}, id='6c089ba5-e0dd-4700-87f8-2af39636bf2 |
なお、上記はStateにメッセージを追加する方法となります。
LLMがすでに回答したメッセージを直接上書きするにはメッセージのIDを指定する必要があるようです。
Part 6: Customizing State
このセクションではグラフが利用するStateに新しいフィールドを追加して、より複雑なフローを定義できるようにします。
Part4, 5ではTool useの前には必ず中断するようにグラフを定義していましたが、人間に介入させるかどうかの選択肢をグラフに持たせるようにします。
シナリオとしては、このLLMアプリを使うユーザーのほかにアプリ運営側に「専門家」がいるとします。ユーザーがLLMアプリでは回答できない専門的な質問を行った場合に、「専門家」に対してユーザーの質問をエスカレーションするTool use機能をこのセクションで追加します。
グラフは以下のようになります。
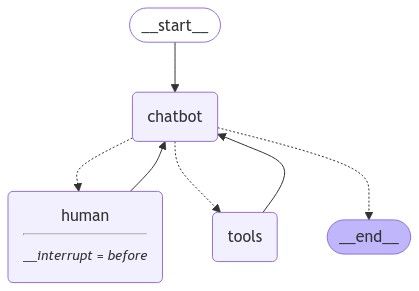
Part5からのコードの変更点は以下の通りです。
- Stateにask_humanフラグを追加
- RequestAssistanceクラスを「人間の専門家にユーザーの要求をエスカレーションするTool」として追加し、Web検索のToolsと同様にLLMにバインド
- 「専門家」の介入後に動作するhuman_nodeノードを追加。直前に「専門家」が介入した場合、ask_humanフラグを解除する。「専門家」が応答をしなかった場合も、「No response ~」というメッセージを返して、ask_humanフラグを解除しフローを続行する。
- ソースコード
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102103104105106107108109110111112113114115116117118119120121122123124125126127128129130131132133# 省略class State(TypedDict):messages: Annotated[list, add_messages]# human_nodeを呼び出すかのフラグask_human: bool# 専門家にサポートを依頼するToolを定義class RequestAssistance(BaseModel):"""専門家に会話をエスカレーションします。直接支援できない場合や、ユーザーがあなたの権限を超えるサポートを必要とする場合にこれを使用してください。この機能を使用するには、専門家が適切なガイダンスを提供できるように、ユーザーの'request'(要求)を伝えてください。"""request: str# toolを定義tool = TavilySearchResults(max_results=2)tools = [tool]llm = ChatBedrockConverse(model="anthropic.claude-3-5-sonnet-20240620-v1:0")# LLMに使用できるtoolをバインドllm_with_tools = llm.bind_tools(tools + [RequestAssistance])def chatbot(state: State):# LLMをinvokeresponse = llm_with_tools.invoke(state["messages"])# LLMのレスポンスがtool useかつRequestAssistanceツールを指定のとき、ask_humanフラグを立てるask_human = Falseif (response.tool_callsand response.tool_calls[0]["name"] == RequestAssistance.__name__):ask_human = Truereturn {"messages": [response], "ask_human": ask_human}# グラフを定義graph_builder = StateGraph(State)# chatbot, toolsノードをグラフに定義graph_builder.add_node("chatbot", chatbot)graph_builder.add_node("tools", ToolNode(tools=[tool]))def create_response(response: str, ai_message: AIMessage):return ToolMessage(content=response,tool_call_id=ai_message.tool_calls[0]["id"])def human_node(state: State):new_message = []if not isinstance(state["messages"][-1], ToolMessage):# 「専門家」が応答をしない場合、「No response ~」というメッセージを返して、「専門家」が介入したと仮定してフローを続行する。new_message.append(create_response("No response from human.", state["messages"[-1]]))return{# 新しいメッセージを追加"messages": new_message,# フラグを解除"ask_human": False}graph_builder.add_node("human", human_node)def select_next_node(state: State):# ask_humanフラグがtrueの時humanノードを選択if state["ask_human"]:return "human"# ask_humanフラグがfalseのときtoolsノードを選択return tools_condition(state)# chatbotノード実行後の条件付きエッジにselect_next_nodeを追加graph_builder.add_conditional_edges("chatbot",select_next_node,{"human": "human", "tools": "tools", END: END},)graph_builder.add_edge("tools", "chatbot")graph_builder.add_edge("human", "chatbot")graph_builder.set_entry_point("chatbot")memory = MemorySaver()graph = graph_builder.compile(checkpointer=memory,interrupt_before=["human"])config = {"configurable": {"thread_id": "1"}}def stream_graph_updates(user_input: str):events = graph.stream({"messages": [("user", user_input)]}, config, stream_mode="values")for event in events:if "messages" in event:event["messages"][-1].pretty_print()def stream_graph_updates_by_none():events = graph.stream(None, config, stream_mode="values")for event in events:if "messages" in event:event["messages"][-1].pretty_print()def update_graph_state():snapshot = graph.get_state(config)ai_message = snapshot.values["messages"][-1]human_response = ("私たち専門家がお手伝いします!エージェントを構築するにはLangGraphをチェックすることをお勧めします。""単純な自律エージェントよりもはるかに信頼性が高く、拡張性があります。")tool_message = create_response(human_response, ai_message)graph.update_state(config, {"messages": [tool_message]})print(graph.get_state(config).values["messages"])while True:try:user_input = input("User: ")if user_input.lower() in ["quit", "exit", "q"]:print("Goodbye!")breakelif user_input == "":stream_graph_updates_by_none()elif user_input == "update":update_graph_state()else:stream_graph_updates(user_input)except:user_input = "What do you know about LangGraph?"print("User: " + user_input)stream_graph_updates(user_input)break
実行結果は以下のようになります
- まずユーザー入力として「AIエージェントの構築に専門家のサポートが必要です。サポートを依頼できますか?」と質問しました。これは専門家の介入が必要な質問のため、RequestAssistanceがTool useされています。
- 専門家からの入力を再現するためにupdateを入力します。
- 専門家からの入力をもとにLLMが回答を生成しています。
- 続いてユーザー入力として「LangGraphの一般的な特徴について教えてください」と質問しました。この場合、LLMはWeb検索のTool use選択し、その検索結果で回答を生成しています。
というように、LLMがユーザーの入力に応じて使用するToolを選択していることがわかります。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 |
User: AIエージェントの構築に専門家のサポートが必要です。サポートを依頼できますか? ================================ Human Message ================================= AIエージェントの構築に専門家のサポートが必要です。サポートを依頼できますか? ================================== Ai Message ================================== [{'type': 'text', 'text': 'もちろん、AIエージェントの構築に関する専門家のサポートをリクエストすることができます。このような専門的な支援を得るために、専門家へのエスカレーションを行う機能を使用しましょう。あなたの要求をより具体的に伝えることで、適切な専門家からの支援を受けられる可能性が高くなります。\\n\\nそれでは、専門家への支援リクエストを行いましょう。'}, {'type': 'tool_use', 'name': 'RequestAssistance', 'input': {'request': 'AIエージェントの構築に関する専門 家のサポートが必要です。特に、エージェントの設計、開発、トレーニング、そして倫理的な考慮事項について助言が欲しいです。'}, 'id': 'tooluse_QtI_fPLMTiKz0UPEShIbOw'}] Tool Calls: RequestAssistance (tooluse_QtI_fPLMTiKz0UPEShIbOw) Call ID: tooluse_QtI_fPLMTiKz0UPEShIbOw Args: request: AIエージェントの構築に関する専門家のサポートが必要です。特に、エージェントの設計、開発、トレーニング、そして倫理的な考慮事項について助言が欲しいです。 User: update [HumanMessage(content='AIエージェントの構築に専門家のサポートが必要です。サポートを依頼できますか?', additional_kwargs={}, response_metadata={}, id='5a002150-b159-4503-8e80-3082406745e6'), AIMessage(content=[{'type': 'text', 'text': 'もちろん、AIエージェントの構築に関する専門家のサポートをリクエストすることができます。このような専門的な支援を得るために、専門家へのエスカレーションを行う機能を使用しましょう。あなたの要求をより具体的に伝えることで、適切な専門 家からの支援を受けられる可能性が高くなります。\\n\\nそれでは、専門家への支援リクエストを行いましょう。'}, {'type': 'tool_use', 'name': 'RequestAssistance', 'input': {'request': 'AIエージェントの構築に関する専門家のサポートが必要です 。特に、エージェントの設計、開発、トレーニング、そして倫理的な考慮事項について助言が欲しいです。'}, 'id': 'tooluse_QtI_fPLMTiKz0UPEShIbOw'}], additional_kwargs={}, response_metadata={'ResponseMetadata': {'RequestId': '4abe6a98-96be-4acf-a2f7-4b7cafe33ac9', 'HTTPStatusCode': 200, 'HTTPHeaders': {'date': 'Wed, 09 Oct 2024 14:49:16 GMT', 'content-type': 'application/json', 'content-length': '1006', 'connection': 'keep-alive', 'x-amzn-requestid': '4abe6a98-96be-4acf-a2f7-4b7cafe33ac9'}, 'RetryAttempts': 0}, 'stopReason': 'tool_use', 'metrics': {'latencyMs': 5638}}, id='run-8091856c-0ef2-4fcf-8d29-9d2d7044c9b1-0', tool_calls=[{'name': 'RequestAssistance', 'args': {'request': 'AIエージェン トの構築に関する専門家のサポートが必要です。特に、エージェントの設計、開発、トレーニング、そして倫理的な考慮事項について助言が欲しいです。'}, 'id': 'tooluse_QtI_fPLMTiKz0UPEShIbOw', 'type': 'tool_call'}], usage_metadata={'input_tokens': 1013, 'output_tokens': 253, 'total_tokens': 1266}), ToolMessage(content='私たち専門家がお手伝いします!エージェントを構築するにはLangGraphをチェックすることをお勧めします。単純な自律エージェントよりもはるかに信頼性が高く、拡 張性があります。', id='41f42c25-00a9-4c1e-a87e-567eeca38842', tool_call_id='tooluse_QtI_fPLMTiKz0UPEShIbOw')] User: ================================= Tool Message ================================= 私たち専門家がお手伝いします!エージェントを構築するにはLangGraphをチェックすることをお勧めします。単純な自律エージェントよりもはるかに信頼性が高く、拡張性があります。 ================================= Tool Message ================================= 私たち専門家がお手伝いします!エージェントを構築するにはLangGraphをチェックすることをお勧めします。単純な自律エージェントよりもはるかに信頼性が高く、拡張性があります。 ================================== Ai Message ================================== 専門家からの回答をいただきました。専門家は、AIエージェントの構築にLangGraphを推奨しています。LangGraphは、単純な自律エージェントよりも信頼性が高く、拡張性があるとのことです。 この情報を元に、以下のようなステップを提案します: 1. LangGraphについて詳しく調べる: LangGraphの特徴、使い方、利点について学習してください。 2. エージェントの設計: LangGraphを使用してエージェントの基本構造を設計します。目的、機能、インターフェースなどを明確にしましょう。 3. 開発環境の準備: LangGraphをインストールし、開発環境をセットアップします。 4. エージェントの開発: 設計に基づいて、LangGraphを使用してエージェントを実装します。 5. トレーニングとテスト: エージェントの性能を向上させるためのトレーニングを行い、様々なシナリオでテストします。 6. 倫理的考慮: AIの倫理ガイドラインを参照し、エージェントが倫理的に行動するよう設計します。 7. 継続的な改善: フィードバックを基にエージェントを改善し、新しい機能を追加します。 これらのステップを進める中で、さらに具体的な質問や課題が出てきた場合は、再度専門家のサポートを求めることができます。AIエージェントの構築は複雑なプロセスですが、LangGraphを使用することで、より信頼性の高い拡張性のあるシステムを構築できる可能性があります。 何か特定の部分について、さらに詳しい情報や支援が必要でしょうか? User: LangGraphの一般的な特徴について教えてください ================================ Human Message ================================= LangGraphの一般的な特徴について教えてください ================================== Ai Message ================================== [{'type': 'text', 'text': 'LangGraphについての一般的な特徴を調べるために、最新の情報を検索してみましょう。'}, {'type': 'tool_use', 'name': 'tavily_search_results_json', 'input': {'query': 'LangGraph features and characteristics for AI agent development'}, 'id': 'tooluse_YiAbZB7oQMqAiwW3TWZLRg'}] Tool Calls: tavily_search_results_json (tooluse_YiAbZB7oQMqAiwW3TWZLRg) Call ID: tooluse_YiAbZB7oQMqAiwW3TWZLRg Args: query: LangGraph features and characteristics for AI agent development ================================= Tool Message ================================= Name: tavily_search_results_json [{"url": "<https://www.geeky-gadgets.com/using-langgraph-to-build-ai-agents/>", "content": "LangGraph AI Agent Development Key Takeaways : LangGraph is a tool compatible with LangChain V2, designed to develop advanced AI agents, particularly research agents."}, {"url": "<https://adasci.org/a-practical-guide-to-building-ai-agents-with-langgraph/>", "content": "Key Components of LangGraph. LangGraph simplifies AI agent development by focusing on three key components: State: The State is an accurate representation of the current status of the agent. Node: Nodes are the building blocks executing computations. The nodes can be LLM-based, Python code. Each graph execution builds a state, and this is ..."}] ================================== Ai Message ================================== 検索結果から得られたLangGraphの一般的な特徴について、以下にまとめます: 1. LangChain V2との互換性: LangGraphはLangChain V2と互換性があり、これにより既存のLangChainプロジェクトとの統合が容易になります。 2. 高度なAIエージェント開発: 特に研究エージェントなど、高度なAIエージェントの開発に適しています。 3. シンプルな構造: LangGraphは、AIエージェント開発を簡素化するために3つの主要コンポーネントに焦点を当てています: a. State(状態): - エージェントの現在の状況を正確に表現します。 - 各グラフ実行で状態が構築されます。 b. Node(ノード): - 計算を実行する基本的な構成要素です。 - LLM(大規模言語モデル)ベースのものやPythonコードで構成できます。 c. Graph(グラフ): - ノードを接続して全体のワークフローを形成します。 4. 柔軟性: LLMベースのノードとPythonコードを組み合わせることで、多様な機能を持つエージェントを作成できます。 5. 拡張性: グラフ構造により、エージェントの機能を段階的に拡張したり、複雑なワークフローを構築したりすることが可能です。 6. 状態管理: グラフの実行ごとに状態が構築され、エージェントの一貫した動作と長期的なタスク管理をサポートします。 7. 研究向け最適化: 特に研究エージェントの開発に適しており、複雑な情報処理や長期的なタスク管理が必要な場面で力を発揮します。 8. モジュール性: ノードベースの設計により、エージェントの各機能を独立したモジュールとして開発・管理できます。 これらの特徴により、LangGraphは単純な自律エージェントよりも信頼性が高く、拡張性のあるAIエージェントを構築するのに適しています。特に複雑なタスクや長期的な目標を持つエージェントの開発に有効です。 LangGraphの特定の側面について、さらに詳しい情報が必要ですか?それとも、これらの特徴を踏まえてAIエージェントの開発に関して具体的な質問があり |
Part 7: Time Travel
最後のセクションです。
このセクションではTime travel機能を使い、グラフの状態を特定の状況に巻き戻してみます。
これにより任意の個所からワークフローの分岐をやり直したり、別の結果を誘導させることができるようになります。
Part6のグラフから内容自体は変わりませんが、ユーザーからの入力のバリエーションを増やしてみます。
- replayを入力すると、graph.get_state_history()でこれまでの会話履歴を取得して表示します。
- to_replay {checkpoint_id}を入力すると、会話履歴の特定のチェックポイントにさかのぼります。
- ソースコード
123456789101112131415161718192021222324252627282930313233343536# 省略# チャットの履歴を表示するdef replay_chat():for state in graph.get_state_history(config):print("Num Messages: ", len(state.values["messages"]), "Next: ", state.next)print(state.config)print("-" * 80)# 引数に渡したcheckpoint_idの箇所まで巻き戻すdef to_replay(checkpoint_id: str):replay_config = {'configurable': {'thread_id': '1', 'checkpoint_ns': '', 'checkpoint_id': checkpoint_id}}for event in graph.stream(None, replay_config, stream_mode="values"):if "messages" in event:event["messages"][-1].pretty_print()while True:try:user_input = input("User: ")if user_input.lower() in ["quit", "exit", "q"]:print("Goodbye!")breakelif user_input == "":stream_graph_updates_by_none()elif user_input == "update":update_graph_state()elif user_input == "replay":replay_chat()elif user_input.startswith("to_replay"):to_replay(user_input.split()[1])else:stream_graph_updates(user_input)except Exception as e:print(e)break
実行結果は以下のようになります
- まずは私の年齢をインプットします。
- 続けて明日の天気を聞きます。
- 続けて私の名前をインプットします。
- ここでreplayを入力し、会話履歴を表示させます。
- 序盤のメッセージ数1のときのcheckpoint_idをto_replayで渡してグラフの状態を巻き戻します。
- 私の名前を聞いてみましたが、名前をインプットしたのはこのチェックポイントより後のため、参照できずに答えられない状態になっていることが確認できました。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 |
User: 私は29歳です ================================ Human Message ================================= 私は29歳です ================================== Ai Message ================================== ありがとうございます。29歳というお年齢をお聞かせいただきましたが、具体的に何かお手伝いできることはございますか?例えば、29歳に関連した情報や、その年齢での一般的な関心事などについてお知りになりたいことはありますか? もし特定の質問や話題がありましたら、お聞かせください。そうすれば、より適切なサポートや情報提供ができるかもしれません。 User: 明日の東京の天気はどうでしょうか? ================================ Human Message ================================= 明日の東京の天気はどうでしょうか? ================================== Ai Message ================================== [{'type': 'text', 'text': '明日の東京の天気について調べるために、検索エンジンを使用して最新の情報を取得します。'}, {'type': 'tool_use', 'name': 'tavily_search_results_json', 'input': {'query': '明日の東京の天気予報'}, 'id': 'tooluse_6YzAiiafRyim9jgaL_nXyg'}] Tool Calls: tavily_search_results_json (tooluse_6YzAiiafRyim9jgaL_nXyg) Call ID: tooluse_6YzAiiafRyim9jgaL_nXyg Args: query: 明日の東京の天気予報 ================================= Tool Message ================================= Name: tavily_search_results_json [{"url": "<https://weather.yahoo.co.jp/weather/jp/13/4410.html>", "content": "東京(東京)の天気予報。今日・明日の天気と風と波、明日までの6時間ごとの降水確率と最高・最低気温を見られます。"}, {"url": "<https://weather.yahoo.co.jp/weather/jp/13/>", "content": "東京都の天気予報。今日の天気、明日の天気、気温、降水確率を地図上に表示。近隣地域の天気も一目でわかります。"}] ================================== Ai Message ================================== 申し訳ありませんが、検索結果からは明日の東京の具体的な天気予報を直接確認することができませんでした。ただし、以下の情報を共有できます: 1. Yahoo!天気のウェブサイトで東京の天気予報を確認できます。 2. これらのウェブサイトでは、今日と明日の天気、風、波の状況、6時間ごとの降水確率、最高・最低気温などの情報が提供されています。 明日の正確な天気予報を知るには、以下のいずれかの方法をお勧めします: 1. Yahoo!天気の東京のページ(<https://weather.yahoo.co.jp/weather/jp/13/4410.html)を直接訪問する。> 2. 日本気象庁の公式ウェブサイトを確認する。 3. お使いのスマートフォンの天気アプリを確認する。 これらの方法で、明日の東京の天気に関する最新かつ正確な情報を得ることができます。天気予報は常に更新されているため、最新の情報を確認することが重要です。 何か他に気象情報に関して知りたいことはありますか?あるいは、他の質問がございましたら、お聞かせください。 User: 私の名前はYokomachiです ================================ Human Message ================================= 私の名前はYokomachiです ================================== Ai Message ================================== はい、Yokomachiさん。お名前をお教えいただき、ありがとうございます。Yokomachiさんとしてお話しできることを嬉しく思います。 何かご質問やお手伝いできることはありますか?例えば: 1. 特定の情報をお探しですか? 2. 何か相談したいことはありますか? 3. 趣味や興味のあることについて話したいですか? 4. 日常生活や仕事に関連したアドバイスが必要ですか? どのようなことでも、できる限りサポートさせていただきますので、お気軽にお話しください。 User: replay Num Messages: 8 Next: () {'configurable': {'thread_id': '1', 'checkpoint_ns': '', 'checkpoint_id': '1ef8656e-2d29-6104-8009-840cb5e8731a'}} -------------------------------------------------------------------------------- Num Messages: 7 Next: ('chatbot',) {'configurable': {'thread_id': '1', 'checkpoint_ns': '', 'checkpoint_id': '1ef8656d-f832-6220-8008-943ebb6e044b'}} -------------------------------------------------------------------------------- Num Messages: 6 Next: ('__start__',) {'configurable': {'thread_id': '1', 'checkpoint_ns': '', 'checkpoint_id': '1ef8656d-f82f-695e-8007-6608f0d28a77'}} -------------------------------------------------------------------------------- Num Messages: 6 Next: () {'configurable': {'thread_id': '1', 'checkpoint_ns': '', 'checkpoint_id': '1ef8656d-7511-6c3b-8006-96aabd6d6193'}} -------------------------------------------------------------------------------- Num Messages: 5 Next: ('chatbot',) {'configurable': {'thread_id': '1', 'checkpoint_ns': '', 'checkpoint_id': '1ef8656d-217d-64d1-8005-c2f4f9d78555'}} -------------------------------------------------------------------------------- Num Messages: 4 Next: ('tools',) {'configurable': {'thread_id': '1', 'checkpoint_ns': '', 'checkpoint_id': '1ef8656d-03e0-6612-8004-01a3ed260dd7'}} -------------------------------------------------------------------------------- Num Messages: 3 Next: ('chatbot',) {'configurable': {'thread_id': '1', 'checkpoint_ns': '', 'checkpoint_id': '1ef8656c-ee45-60a6-8003-4779b342ccf2'}} -------------------------------------------------------------------------------- Num Messages: 2 Next: ('__start__',) {'configurable': {'thread_id': '1', 'checkpoint_ns': '', 'checkpoint_id': '1ef8656c-ee42-6473-8002-373667ec91be'}} -------------------------------------------------------------------------------- Num Messages: 2 Next: () {'configurable': {'thread_id': '1', 'checkpoint_ns': '', 'checkpoint_id': '1ef8656c-71b9-669e-8001-f09bb83f890a'}} -------------------------------------------------------------------------------- Num Messages: 1 Next: ('chatbot',) {'configurable': {'thread_id': '1', 'checkpoint_ns': '', 'checkpoint_id': '1ef8656c-4952-6fbf-8000-0a64f0970033'}} -------------------------------------------------------------------------------- Num Messages: 0 Next: ('__start__',) {'configurable': {'thread_id': '1', 'checkpoint_ns': '', 'checkpoint_id': '1ef8656c-494f-6f58-bfff-f247be3a63e9'}} -------------------------------------------------------------------------------- User: to_replay 1ef8656c-4952-6fbf-8000-0a64f0970033 ================================ Human Message ================================= 私は29歳です ================================== Ai Message ================================== はい、ありがとうございます。29歳というお年齢をお聞きしました。しかし、この情報だけでは具体的な質問や要望が分からないため、適切な対応をすることが難しいです。 何か特定の質問や、お手伝いできることはありますか?例えば、29歳に関連して健康、キャリア、ライフスタイルなどについて知りたいことや相談したいことはありますか?もう少し詳しくお聞かせいただければ、より適切にお答えできると思います。 User: 私の名前は何でしょうか? ================================ Human Message ================================= 私の名前は何でしょうか? ================================== Ai Message ================================== 申し訳ありませんが、私にはあなたの名前を知る方法がありません。私は人工知能のアシスタントで、この会話の文脈から得られる情報以外は持ち合わせていません。 これまでの会話では、あなたが29歳であることは伺いましたが、お名前については言及されていません。 もし私にあなたのお名前を教えていただければ、それを覚えて今後の会話で使用することができます。あるいは、もし別の質問や話題がございましたら、お気軽にお聞かせください。お手伝いできることがあれば喜んで対応させ |
おわりに
というわけで長くなりましたが、LangGraphのQuick Start全7パートをやってみました。
まだ理解が追いつかない部分も多くありますが、概観や特徴をつかむのにはよい練習になりました。
また実際に手元でグラフのワークフローが動くのは単純に面白いですね。
今後もLLM関連のライブラリには知見を深めていきたいですし、ノーコード・ローコードアプリとの組み合わせだとか、より複雑なグラフの構築なども試して、自信を持ってLLMアプリ開発できますと言えるくらいにスキルを身に着けていきたいところです。
参考
- Home | LangGraph
- LangGraphとは – テックブログ
- グラフ理論入門 | DevelopersIO
- AWSで生成AIエージェントを操る! 話題のLangGraphにBedrockで入門しよう #langchain – Qiita
- LangGraphのQuickStartを写経した。(前半) #langchain – Qiita
- 【2024】AWS Jr.Championsを振り返る - 2025-07-01
- 中級figma教室 - 2024-12-24
- おすすめガジェット紹介!2024年12月編 - 2024-12-21
- 【Amazon RDS】意図せず突発的な再起動が起こった原因 - 2024-12-19
- Amazon ConnectでNGワードをリアルタイムに検知してSlackに通知する - 2024-12-16
【採用情報】一緒に働く仲間を募集しています